
Threat Hunting Phishing Domains in Golang
Starting point
A few months ago, I decided to focus on Threat Hunting and what tool I could create to hunt myself and find malicious behavior and attackers.
An idea occurred to me: many people in my entourage asked me if this “text message” or this “email” was legit, especially the URL link there. Of course 90% of the time, it was smishing or phishing campaigns.
After that, I wondered how I could anticipate the attackers. Here is the reasoning I had: Most phishing sites have domains that have been registered very recently with a registrar (usually less than 2 weeks). As a result, I already have a lead on which element I will rely on to detect potential phishing domains.
Then I started thinking about how to do it and in what language.
Methodology
Here is my point of view:
- First, I need to get feed of newly registered domains
- Domains databases do not exceed 30 days
- Grep keywords of tiposquatting legit domains which are most often usurped
- Test if domains responds to HTTP/S requests (WEB Server Online ?)
- Report those which are malicious on online CTI platforms
Newly Registered Domains Feed
There is the difficult part: Get a good and a full feed for free ! :(
For now, I used WHOISDS which have ~100k entries of new registered domains everyday in the sample they provided to download completely free.
During the writing of this article, I fount out Afnic data share for all new domains registered with the TLD .fr. (Thanks to @mikolajek).
In the future, a richer data source should be found (ongoing).
Programming
Don’t ask why but I choose Golang for this project :) This is also the first time I use this programming language and I already love it!
(I’m using the 1.19 version of Golang).
# go version
go version go1.19.2 linux/amd64
Catch TypoSquat
The goal is to pass keywords of legitimate services like “Netflix” or “Chronopost” or everything you want and all the domains matching are printed in output.
The best way for doing it I found is to use Regex (also very fast).
package main
import (
"fmt"
"bufio"
"os"
"regexp"
"flag"
)
// List of keywords we want to find from domains file using regex
var domains = regexp.MustCompile(`gmail|paypal|amazon|facebook|icloud|apple|outlook|hotmail|twitter|whatsapp|telegram|netflix|ameli|cpf|pole-emploi|vitale|orange|banque|sfr|postale|paiement|payment|impot|client`)
func main() {
// flag argparse for options (-f and -h)
var file_urls string
var file_output string
flag.StringVar(&file_urls, "f", "", "url file to test")
flag.StringVar(&file_output, "o", "", "file name output")
flag.Parse()
// Opening domains text file in input with the -f options parameter
urls, err := os.Open(file_urls)
if err != nil {
fmt.Println("You need to add your CSV file with the -f parameter")
}
// Output to a file options (here creation if there is a -o parameter)
file_out, _ := os.Create(file_output)
defer file_out.Close()
if err != nil {
fmt.Println("[OPTIONAL] You need to add the name of output file with the -o parameter")
}
// Now the main part of the program
// Loop for each lines of the file
list_urls := bufio.NewScanner(urls)
for list_urls.Scan() {
line := list_urls.Text()
if len(line) == 0 {
// skip blank lines
continue
}
// Print for domains contains one of keyword pattern from the regex variable
if domains.MatchString(line) {
fmt.Println("Found ! :", line)
// Write to the output file for domains matching (-o option)
fmt.Fprintf(file_out, "%s\n", line)
continue
}
}
}
Testing out the script:
# go run . -f domains.txt -o output.txt
Found ! : aamazonevisiteurs.fr
Found ! : aamazon.fr
Found ! : aamazon.fr
Found ! : a-ameli.fr
Found ! : abanque.fr
Found ! : abcmonimpot.fr
Found ! : abcmonimpot.fr
Found ! : abeille-assurances-clients.fr
Found ! : abglassfrance.fr
Found ! : abicloud.fr
Found ! : abiesfrance.fr
Found ! : abigmail.fr
Found ! : abmsfrance.fr
Found ! : aboclient.fr
Found ! : abonnement-client.fr
Found ! : abonnement-clients.fr
Found ! : abonnement-netflix.fr
Found ! : abonnement-netflixweb.fr
Found ! : abonnement-orange.fr
...
Here we go, the script is very fast and we can already see “Netflix” typosquatting websites.
WEB Server Response
Now we have a good list of domains that potentially usurped legitimate companies and services.
Then we tested out which domain responds to Web requests (HTTP/S).
package main
import (
"bufio"
"crypto/tls"
"fmt"
"net/http"
"os"
"time"
"flag"
)
func main() {
// flag argparse for options (-f and -h)
var file_urls string
flag.StringVar(&file_urls, "f", "", "url file to test")
flag.Parse()
// Opening parsed domains text file from the precedent output script in input with the -f options parameter
urls, err := os.Open(file_urls)
if err != nil {
fmt.Println("You need to add your CSV file with the -f parameter")
}
// Now the main part of the program
// Loop for each lines of the file
list_urls := bufio.NewScanner(urls)
for list_urls.Scan() {
line := list_urls.Text()
if len(line) == 0 {
// skip blank lines
continue
}
// Ignore SSL Auto-Signed Certificate
transCfg := &http.Transport{
TLSClientConfig: &tls.Config{
InsecureSkipVerify: true}, // ignore expired SSL certificates
}
client := &http.Client{
Timeout: 10 * time.Second, // Timeout (10 sec for each domain)
Transport: transCfg,
}
// Get Request for each domain (https)
resp, err := client.Get("https://" + line)
if err != nil {
fmt.Println("No Host :", line)
continue
}
// Get status code
status_code := resp.StatusCode
fmt.Println(status_code, ":", line)
}
}
Testing out the script:
# go run . -f output.txt
No Host : abonnement-netflix.fr
No Host : abonnement-netflixweb.fr
No Host : abonnements-netflix.fr
No Host : access-netflix.fr
No Host : account-netflix.fr
No Host : accueil-netflix.fr
No Host : activation-netflix.fr
No Host : aide-netflix.fr
200 : fans2netflix.fr
No Host : forfait-netflix.fr
No Host : formulaire-aide-netflix.fr
No Host : france-netflix.fr
200 : freenetflix.fr
No Host : fr-netflix.fr
No Host : fr-supportnetflix.fr
No Host : groupe-mynetflixeurope.fr
No Host : groupe-mynetflix.fr
No Host : groupe-mynetflixfrance.fr
No Host : groupe-mynetflixfr.fr
No Host : help-netflix.fr
No Host : identification-netflix.fr
No Host : inc-netflix.fr
No Host : info-netflix.fr
No Host : infonetflix.fr
200 : information-netflix.fr
No Host : informations-netflix.fr
No Host : infos-netflix.fr
No Host : ir-netflix.fr
No Host : isnetflixsecure.fr
No Host : login-netflix-connexion.fr
No Host : mon-abonnement-netflix.fr
No Host : monabonnement-netflix.fr
No Host : monabonnementnetflix.fr
No Host : moncomptenetflix-connexion.fr
No Host : mon-compte-netflix.fr
No Host : moncompte-netflix.fr
No Host : moncomptenetflix.fr
200 : mon-renouvelement-netflix.fr
No Host : mon-renouvellement-netflix.fr
200 : myaccount-netflix.fr
Most of the domains are actually not responding (maybe because in this example I choose a very recent feed ~1-3 days ago) but we found out some with code 200 (OK Status) !
I decided to inspect those with code 200 (visually on my browser):
https://information-netflix[.]fr
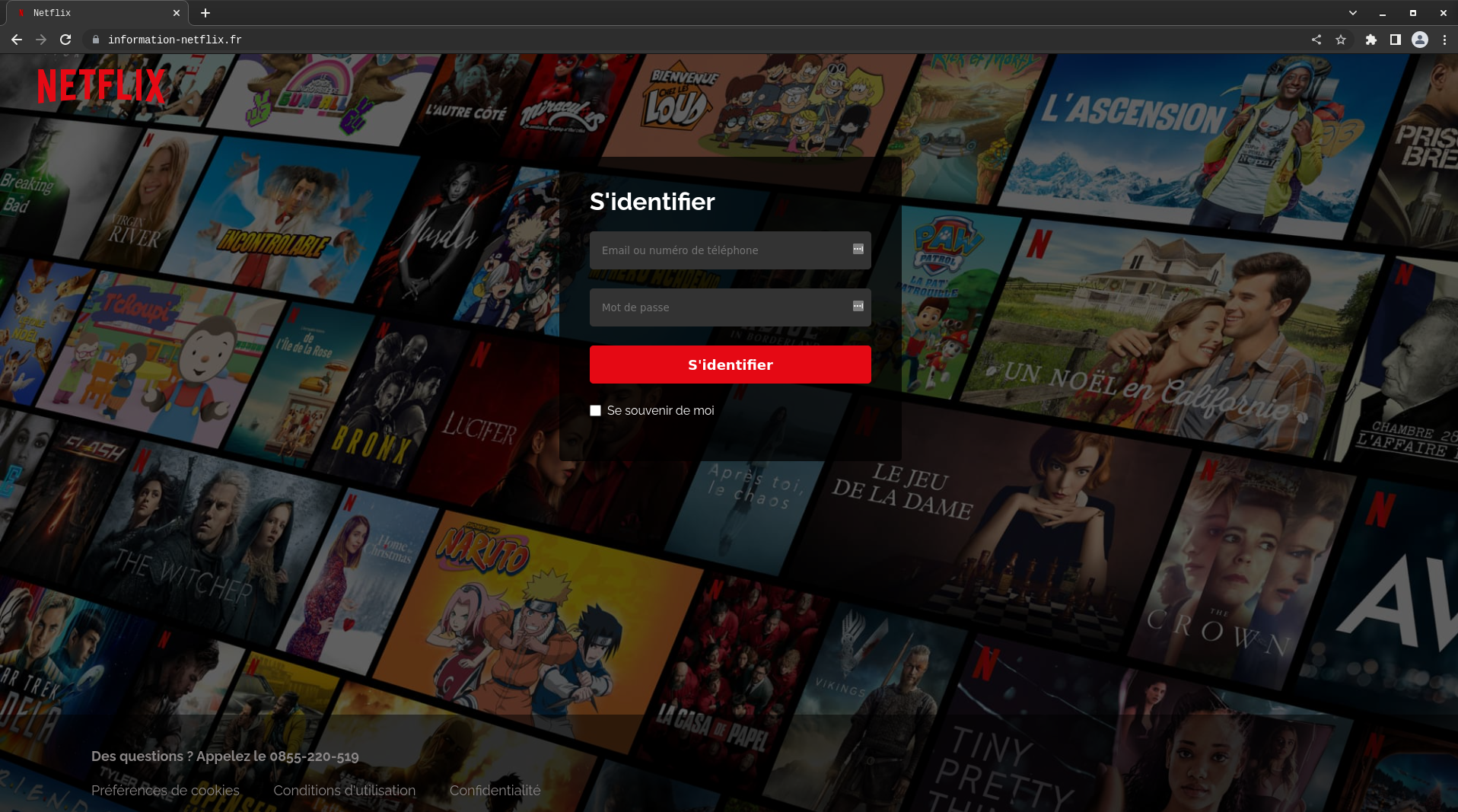
Bingo! We got our first malicious hit on Netflix Phishing website.
Let’s report that to reduce the impact of people falling in the trap.
Reporting
There are many ways to report phishing websites. Usually I choose Phishing Initiative, developed by the CERT of Orange Cyberdéfense (France). Everyone can report phishing URL and after they do the job to end the malicious website.
Finale Notes
Note that there are the basics for threat hunting phishing website, I’m currently working on a more complete project (private Git for now) for great more options and capabilities.
I wanted to do an “intro” on this article to show that quickly we can hunt these sites for free.
Thank you for those who read the article, do not hesitate to contact me by twitter I will answer you with pleasure!